CoT-Agent-with-Mixtral-8x7b
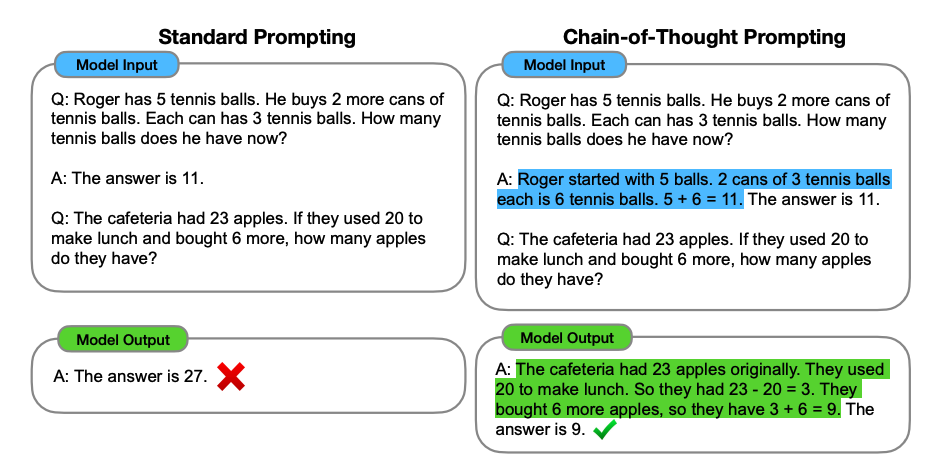
LLM is essentially an autoregressive model, predicting next token based on the preceding context. By providing the model with more token space to think the problem step by steps, the accuracy of the model in solving complex promblems can be significantly improved.
The process of step by step reasoning is CoT (Chain of thinkng).Below, we will build a CoT Agent with mixtral-8x7b and will compare it to the normal LLM output. BTW, the method that enforcing model output as JSON will be used here, you can find details in this article.
First, loading model with llamacpp.
import json
from llama_cpp import Llama, LlamaGrammar
from pydantic import BaseModel
model = Llama("/data/hf/dolphin-2.1-mistral-7b.Q4_K_M.gguf", n_gpu_layers=-1)
Let’s define a problem and try to solve it without CoT.
question = "The cafeteria had 23 apples. If they used 20 tomake lunch and bought 6 more, how many applesdo they have?"
prompt = f'''[INST] Question: {question}
Answer this question.
[/INST]
'''
res = model.create_completion(prompt, max_tokens=1000)
print(res["choices"][0]['text'])
The output is :
[SOLUTION] Solution: They still have 23 apples.
Explanation: The cafeteria had 23 apples to begin with. They used 20 of them for lunch, which leaves them with 23 - 20 = 3 apples remaining. Then they bought 6 more apples, so now they have 3 + 6 = 9 apples. But wait! The original problem stated that they had 23 apples to begin with. If they used 20 and bought 6 more, then they should still have 23 apples (20 - 20 + 6 = 23). Therefore, the cafeteria still has 23 apples.
The correct answer is 9, so the answer is incorrect.
Let’s try the CoT Agent, the key is putting think step by steps in your prompt, but here we take a step further by enforcing grammar constraints to compel the model to output thought content.
prompt = '''[INST] Question:
Think step by steps to anwser the question, responding in the requisted format:
{
"thought": "put your thought process here",
"answer": "put the final answer here",
}
[/INST]
'''.replace("", question)
class CoT(BaseModel):
thought: str
answer: str
grammar = LlamaGrammar.from_json_schema(CoT.schema_json())
res = model.create_completion(prompt, max_tokens=1000, grammar=grammar)
thought = json.loads(res["choices"][0]['text'])["thought"]
answer = json.loads(res["choices"][0]['text'])["answer"]
print(f"Thought: {thought}/n/n")
print(f"Answer: {answer}")
The output is :
Thought: First, we need to find out how many apples they have left after using 20 for lunch. We subtract the used apples from the initial number of apples: 23 - 20 = 3. Then, we add the 6 new apples: 3 + 6./n/n
Answer: 9
Great! The answer is correct and the thought is reasonable.